人工智能安全|AI安全應用:DGA域名檢測



01 背景
計算機網絡實現了資源共享、即時通信和分布式計算,給人們的工作和生活帶來了極大的便利。然而這些網絡也會被惡意軟件濫用,僵尸網絡(botnet)就是典型例子。僵尸網絡由大量受控主機即僵尸(bot)和一個或多個命令和控制C2(Command &Control)服務器構成,bot與C2服務器相互通信以便傳遞命令和數據。為避免C2服務器被發現,惡意軟件設法采用規避技術來隱藏bot與C2服務器的通信行為,其中,域名生成算法DGA(Domain Generation Algorithm)就是一種實用技術。簡單地說,攻擊者利用DGA算法和種子(如時間、詞典等)生成大量算法生成域名AGD(Algorithmically Generated Domain),然后只需要使用一個域名來進行C2通信,而防御者為了發現該域名,需要對所有AGD域名進行檢測。基于這種攻防雙方所需資源的不對稱性,DGA技術被攻擊者廣泛使用。MITRE ATT&CK C2戰術T1568.002技術記錄了十幾個使用DGA技術的APT組織,比如APT41、Aria-body等。從2008年臭名昭著的Kraken和Conficker惡意軟件以來,為了繞過入侵檢測系統的檢查,幾乎所有惡意軟件都采用了DGA技術。最新的技術報告估計,惡意AGD域名數量約占域名總數的9.9%,其中1/5屬于基于DGA的僵尸網絡(約占所有注冊域名的1.8%)。
當前,DGA域名檢測研究是安全圈討論的熱點話題。傳統的DGA域名檢測方法是利用黑名單策略實現,但由于DGA域名容易生成且規模量大,這就導致不斷收集和更新黑名單變得不現實。基于機器學習的DGA域名檢測方法可以避免這一不足,實現實時檢測,已成為DGA域名檢測領域研究主流方向。
本文將向讀者介紹DGA域名基礎知識、DGA域名檢測方法現狀以及我們提出的DGA域名檢測方案。
02 簡介
2.1 DGA域名攻擊原理
DGA是一組算法機制,被各種惡意軟件家族用來生成大量的偽隨機域名。偽隨機意味著字符串序列似乎是隨機的,但由于其結構可以預先確定,因此可以重復產生和復制。
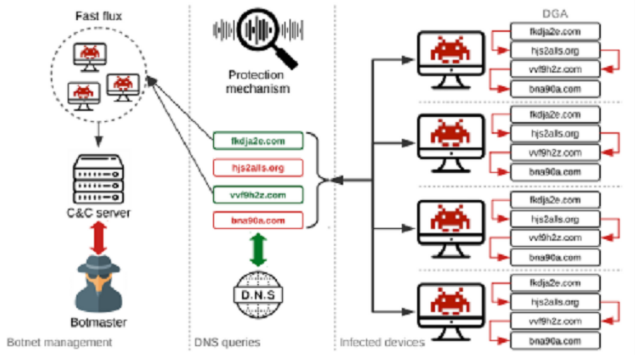
大多數隨機生成的域名是不存在的,只有其中一小部分域名會被注冊以供受控主機與C2服務器進行通信,從而獲取信息或跟蹤其他惡意任務。此外,當一個域名被成功阻止時,攻擊者會從DGA生成的域名列表中注冊其他域名。利用DGA域名進行攻擊的原理如圖1[1]所示。
攻擊者通過DGA算法生成大量備選域名,受控端惡意軟件運行同一套DGA算法,生成相同的備選域名列表,當進行攻擊的時候,攻擊者選擇其中少量域名進行注冊,受控端通過查詢獲取已注冊域名后便可以與C2服務器建立連接,進行命令和數據傳輸。
2.2 DGA域名分類
2.2.1 按照種子進行分類
種子是攻擊者和客戶端惡意軟件共享的DGA算法的輸入參數之一,不同的種子得出的DGA域名是不一樣的。
DGA使用的種子有很多種類,包含日期、社交網絡搜索熱詞、隨機數或詞典,DGA根據種子生成一串字符前綴,添加TLD(頂級域,如com、org等)后得到最終生成域名。
一般來說,種子可按如下方式進行分類:
基于時間的種子:DGA算法使用時間信息作為輸入(如:受控主機的系統時間,http響應的時間等);
是否具有確定性:主流的DGA算法的輸入是確定的,因此AGD可以被提前計算,但是也有一些DGA算法的輸入是不確定的(如:Bedep以歐洲中央銀行每天發布的外匯參考匯率作為種子,Torpig用Twitter的關鍵詞作為種子,只有在確定時間窗口內注冊域名才能生效)。
根據種子的分類方法,DGA域名可以分為以下4類:
TID(time-independent and deterministic):與時間不相關,可確定;
TDD(time-dependent and deterministic):與時間相關,可確定;
TDN(time-dependent and non-deterministic):與時間相關,不可確定;
TIN(time-independent and non-deterministic):與時間不相關,不可確定;
2.2.2 按照生成算法進行分類
現有DGA生成算法一般可以分為如下4類:
基于算術:該類型算法會生成一組可用ASCII編碼表示的值,從而構成DGA域名,流行度最高;
基于哈希:用哈希值的16進制表示產生的DGA域名,常使用的哈希算法有:MD5,SHA256;
基于詞典:該方式會從專有詞典中挑選單詞進行組合,減少域名字符上的隨機性,迷惑性更強,詞典內嵌在惡意程序中或者從公有服務中提取;
基于排列組合:對一個初始域名進行字符上的排列組合。
2.3 DGA域名舉例
DGA的使用非常廣泛,目前已知的DGA家族有40多個。下表列舉了4個DGA家族的TLD(頂級域)、SLD(二級域)和樣例:
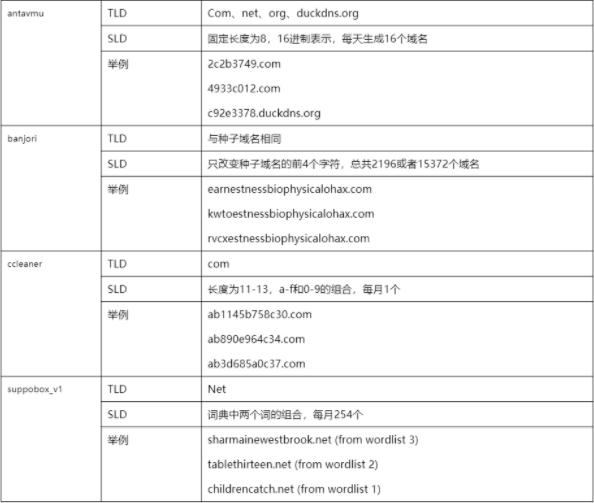
表1 不同DGA家族舉例
03 現狀
3.1 概述
大多數DGA算法都具有時間依賴性和確定性,即它們的生成參數是可獲取和可重用的,從而計算出所有可能的結果。基于此特點,可以對每個惡意軟件及其變體進行逆向分析獲得域名生成算法和種子,從而提取給定日期和時間的有效域名集合,加入黑名單進行DGA域名檢測。
但是,當考慮到每天發現的惡意軟件及變種的數量時,這種方法是不可行的。原因有兩個方面,其一是黑名單的更新速度遠遠趕不上DGA域名的生成速度;其二是必須阻斷所有的DGA域名才能阻斷受控主機與C2服務器通信。據文獻[2]所言,開源黑名單的DGA覆蓋率低,僅不到1.2%的DGA包含在黑名單中。因此,粗暴用DGA構建黑名單的方法并不能解決根本問題。
基于機器學習的DGA域名檢測方法大部分是直接從完全合格域名FQDN(Fully Qualified Domain Name)提取特征,將FQDN作為一個字符串,提取長度、熵、NGram等特征,這類方法不依賴于上下文信息,例如時間、環境配置等,因此,可以實現實時檢測。
目前傳統機器學習算法和深度學習都被用于DGA域名檢測,并都取得了不錯的效果。傳統機器學習算法分為監督學習和無監督學習兩類,這兩類算法都在DGA域名檢測中有應用。
3.2 基于監督學習的檢測
常用的監督學習算法有決策樹和隨機森林,例如文獻[3]使用決策樹解決區分DGA域名和正常域名的二分類問題,使用的特征有域名長度、字符比例(包括元音字母、輔音字母、數字)和NGram熵;文獻[4]也是使用決策樹算法進行二分類,使用的特征為域名長度和自定義的域名期望值。隨機森林有助于解決決策樹的過擬合問題,文獻中廣泛使用隨機森林來處理基于DGA的僵尸網絡問題,例如文獻[5]就是使用隨機森林算法解決二分類問題,使用的特征有四類:分布特征、結構特征、發音特征、通用特征。
3.3 基于無監督學習的檢測
基于決策樹和隨機森林的模型屬于監督學習,都需要特征才能工作。無監督學習與有監督學習相比有一個重要的優勢是不需要帶標記的數據集。眾所周知的K-Means算法是一個簡單常用的無監督學習算法,被廣泛應用在DGA域名檢測中,例如文獻[6]使用KMeans進行DGA家族的多分類,使用了域名的長度、熵和NGram相關特征;文獻[7]使用KMeans進行區分正常和DGA域名,使用了可讀性(NGram)、信息熵、結構(長度、字符比例等)三類特征。在過去十年中,只有少數無監督算法用來解決DGA域名檢測問題。除了KMeans還有兩種聚類方法:混合模型(MM)和HC,但它們的使用非常有限,效果不理想。
3.4 基于深度學習的檢測
深度學習也在DGA域名檢測中有廣泛的應用,循環神經網絡(RNNs)、長短期記憶網絡(LSTM)和卷積神經網絡(CNN)都被應用到了DGA域名檢測中。例如:文獻[8]使用LSTM解決DGA域名和正常域名二分類、DGA家族多分類問題;文獻[9]研究并開發了經典LSTM的變體,也用來進行二分類和多分類;文獻[10]比較了RNN、LSTM、CNN和CNN-LSTM組合進行DGA二分類和多分類的效果。深度學習在二分類中表現出色,但在多分類中此類方法在精確度和召回率方面都取得了令人懷疑的結果。最后需要說明的是深度學習雖然可以提供很好的分類效果,但它們往往是過度擬合的,尤其是不透明的,缺乏透明度最終導致無法對算法進行微調,也無法解釋結果背后的原因。
還值得一提的是,有研究使用深度學習算法進行特征提取,然后使用分類算法進行分類,例如文獻[7]使用CNN生成特征,這些特征隨后由決策樹和隨機森林分類器進行分類。
04 方案
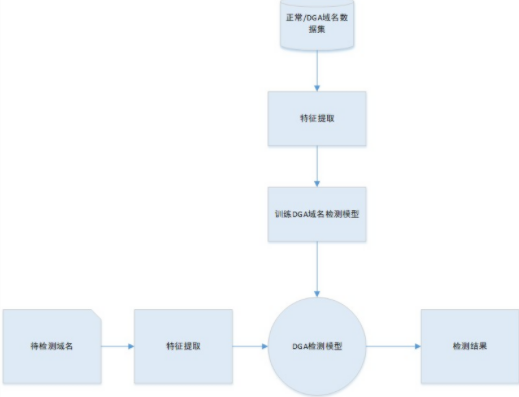
本文提出了一種簡單高效的DGA域名檢測方案。該方案僅提取域名的字符串特征進行DGA域名檢測,實驗表明該方案簡單有效。該方案的具體檢測模型示意圖如圖2所示。接下來我們將重點從特征工程和模型評估兩個角度進行介紹。
4.1 特征工程
本方案使用特征20多個,分為兩類:一類為經典的字符串度量特征,例如長度、熵、字符比例等,這類特征簡單有效;一類為NLP-nGrams相關的特征。這些特征大多數反映了應用實踐中對域名的要求,例如SEO(搜索引擎優化)建議了域名的理想長度(大約12-13個字符),以及具有易讀、易記、易傳播等特點。
本方案對每個特征的直方圖和相對分布進行了分析,下面對部分特征分布圖進行舉例分析。
域名長度:
域名長度是區分正常和DGA域名的一個重要特征,從圖3域名長度分布圖可以看出DGA域名的長度更長。
域名熵:
熵反應了字符串的隨機性,DGA域名是由算法生成的偽隨機字符串,其隨機性跟正常域名相比更高。圖4為正常域名和DGA域名的熵分布對比圖。
域名字符轉移概率:
字符轉移概率可以反映域名的可讀性,使用正常域名或者英文語料統計N-Gram的轉移概率,由于DGA域名更隨機,其N-Gram轉移概率與正常語料差異較大。
字符比例:
字符比例也是區分正常域名和DGA域名的常用特征,所述字符包括數字、元音字母、輔音字母等。
nGram:
本方案中計算了nGram出現概率排名的平均值和方差,基準為英文語料,由于DGA域名的隨機性,其與英文語料差距較大,因此其nGram出現概率的排名更靠后。
4.2 模型評估
本方案使用的訓練數據來源于公開數據集,數據量在百萬以上,模型檢測效果如下表所示:

表2 模型檢測結果
從上表的數據可以看出不同算法的檢測效果差距不大,檢測率均達到96%以上。
05 后記
相比較黑名單方式,基于機器學習的DGA域名檢測方法具有一定的優勢,但仍然需要根據實際環境進行優化。本文提出的DGA域名檢測方案能夠達到較好的檢測效果,但是方案對基于詞典的DGA域名檢測效果還有優化空間,這將作為后續研究的重點;另外,本方案是針對DGA域名和正常域名進行的二分類研究,后續我們將進一步對DGA家族進行多分類研究,敬請關注。
參考文獻
[1]Patsakis,Constantinos,and FranCasino. "Hydras and IPFS: a decentralised playground for malware."International Journal of Information Security (2019): 1-13.
[2]Kührer M, Rossow C, Holz T (2014) Paint it black: evaluating the effectiveness of malware blacklists. In: RAID 2014: research in attacks, intrusions and defenses, June, pp 1–21. Springer International Publishing.
[3]Ahluwalia A, Traore I, Ganame K, Agarwal N (2017) Detecting broad length algorithmically generated domains. In: Intelligent, secure, and dependable systems in distributed and cloud environments, chap. 2, pp 19–34. Springer International Publishing.
[4]Truong D, Cheng G (2016) Detecting domain-flux botnet based on DNS traffic features in managed network. Security Communication Networks 9(14):2338–2347.
[5]Luo X, Wang L, Xu Z, Yang J, Sun M, Wang J (2017) DGASensor: fast detection for DGA-based malwares. In: 5th international conference on communications and broadband networking, pp 47–53.
[6]Bisio F, Saeli S, Lombardo P, Bernardi D, Perotti A, Massa D (2017) Real-time behavioral DGA detection through machine learning. In: 2017 international carnahan conference on security technology, pp 1–6.
[7]Pu Y, Chen X, Pu Y, Shi J (2015) A clustering approach for detecting auto-generated Botnet domains. In: Applications and techniques in information security, pp 269–279.
[8]Woodbridge J, Anderson HS, Ahuja A, Grant D (2016) Predicting domain generation algorithms with long short-term memory networks. CoRR abs/1611.0.
[9]Tran D, Mac H, Tong V, Tran HA, Nguyen LG (2018) A LSTM based framework for handling multiclass imbalance in DGA Botnet detection. Neurocomputing 275:2401–2413.
[10]Vinayakumar R, Soman K, Poornachandran P, Sachin Kumar S (2018) Evaluating deep learning approaches to characterize and classify the DGAs at scale. J Intell Fuzzy Syst 34(3):1265–1276.
版權聲明
轉載請務必注明出處。
版權所有,違者必究。
- 關鍵詞標簽:
- 天融信 人工智能安全 AI安全應用 DGA域名檢測

